
Illustration 1. Choix du formulaire
| Table des matières | Définitions | SATO 4.4, Manuel de référence (décembre 2009) |
| Analyse de la distance (pas-à-pas) | |
|---|---|
|
L'analyseur distance permet de repérer ce qui distingue deux parties d'un corpus en analysant l'utilisation d'un vocabulaire donné dans chacune des deux parties. Dans SATO, ces parties sont appelées des sous-textes. L'analyse est basée sur la distance du Chi2 (Chi carré ou Chi deux) appliquée aux fréquences lexicales de chacun des deux sous-textes à comparer. Par le calcul de distance, on cherche à mesurer la variation d'un vocabulaire donné d'un sous-texte à un autre. La distance est donc ici une mesure d'originalité ou de différenciation dans l'utilisation d'un vocabulaire entre deux sous-textes. L'analyseur distance permet aussi d'indiquer quelles sont les formes lexicales, ou les valeurs de propriété
de ces formes, qui contribuent le plus à la distance entre les deux sous-textes. La particularité de la distance du Chi2 est qu'elle pondère, pour chaque unité de vocabulaire, l'écart de fréquence entre les sous-textes par la fréquence de cette unité de vocabulaire dans l'ensemble du corpus, par exemple. Ainsi, un écart de 1% pour un article fréquent comme « le » contribuera moins à la mesure de distance qu'un écart de 1% pour un mot plus rare. Ce guide propose une description, illustrée pas-à-pas, des opérations techniques à effectuer pour procéder à l'analyse de la distance. Dans ce tutoriel, nous assumons que plusieurs sous-textes ont déjà été créés. Les étapes de création de sous-textes sont illustrées dans le tutoriel Sous-texte avec un filtre (pas-à-pas). Cette illustration suppose une connaissance préalable de notions générales liées à SATO, telle l'utilisation de l'interface web. Voir le chapitre Présentation du logiciel SATO dans le Manuel de référence. | |
|
| |
Dans cet exemple, nous désirons analyser les caractéristiques lexicales qui distinguent un sous-texte d'un autre. Cette illustration présume que nous avons déjà créé au moins deux sous-textes dans notre corpus. Pour plus d'information sur cette opération, on pourra consulter les tutoriels Sous-texte avec un filtre (pas-à-pas) et Scénario (pas-à-pas). Pour illustrer le fonctionnement de l'analyseur distance, nous ferons appel au corpus public dit du Discours constitutionnel canadien (DCC), qui contient les transcriptions de rondes de discussion tenues entre 1941 et 1987 portant sur la constitution canadienne. Dans ce corpus, nous avons déjà créé plusieurs sous-textes correspondant, respectivement, aux allocutions des représentants du gouvernement fédéral, des gouvernements des provinces des Maritimes, ainsi que des représentants des Autochtones et des Inuits. Pour chacun de ces sous-textes, nous avons défini une propriété lexicale entière qui contient la fréquence des mots utilisés dans le sous-texte.
Pour activer l'analyse de distance, dans le menu de SATO à gauche de l'écran, nous choisissons Analyseur, ensuite, Distance et Appliquer tel que présenté dans l'illustration 1 ci-dessous.
Dans un premier temps, nous allons comparer le lexique du sous-texte des déclarations des représentants des Autochtones et Inuits avec celui de l'ensemble des autres représentants (provinciaux et fédéraux). Pour ce faire, dans la liste des propriétés lexicales entières, nous choisissons LexReprAu. Pour rappel, c'est cette propriété qui contient la fréquence des mots utilisés dans le sous-texte des déclarations des représentants des Autochtones et Inuits (cf. étape #5 de la création d'un scénario). On poursuit en cliquant sur le bouton Continuer.
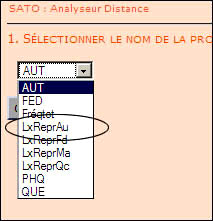
SATO nous demande maintenant de choisir la propriété associée au second sous-texte. Pour comparer les déclarations des représentants des Autochtones et Inuits avec celles de tous les autres représentants, nous choisissons l'étoile (*) dans le menu déroulant du formulaire (voir point 1 sur l'illustration 3 ci-dessous). Dans le contexte de cette commande, l'étoile signifie pour SATO: tout le texte qui est différent du premier sous-texte. La fréquence des mots du deuxième sous-texte sera donc calculée par le logiciel comme la différence entre la fréquence des mots dans l'ensemble du corpus et la fréquence des mots dans le premier sous-texte.
Ensuite, SATO demande d'entrer un filtre lexical qui permet de limiter l'analyse de la distance à un ensemble donné d'entrées dans le lexique du corpus. Ce filtre peut être utilisé pour sélectionner des formes lexicales possédant certaines catégories socio-sémantiques, grammaticales, distributionnelles (par ex: fréquence) ou morphologiques (par ex: longueur). Dans cet exemple, nous sélectionnons tous les mots qui ont une fréquence totale dans le corpus supérieure à trois occurrences et dont la longueur, en nombre de lettres, est supérieure à deux. Comme on le voit dans l'illustration 3 au point 2, la syntaxe pour ce filtre est la suivante: $*fréqtot>3*longueur>2.
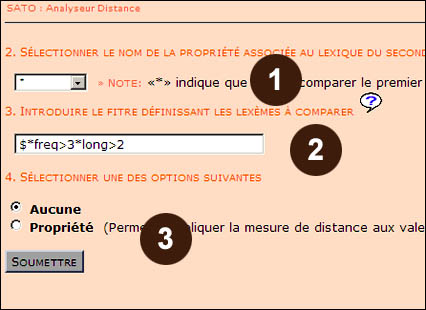
Dans les options du point 3 de l'illustration 3, nous choisissons Aucune parce que nous cherchons à comparer des formes lexicales et non des valeurs de propriété. Ensuite, nous cliquons sur le bouton Soumettre.
Une fois l'analyseur distance appliqué, nous obtenons une page de résultat (cf. illustration 4). Parce que cette page présente de nombreuses informations, elle peut paraitre très complexe. Cependant, elle devrait s'interpréter plus facilement une fois que chaque zone de la page aura été expliquée.
Point 1 de l'illustration 4. Deux indications nous donnent une première idée de ce qui fait la différence entre les déclarations des représentants des Autochtones et Inuits et le reste du corpus. On a d'abord la mesure de la distance. Cette mesure est calculée de la façon suivante. Pour chacun des mots considérés dans la mesure, on calcule (f1-f2)**2 / f0, c'est-à-dire le carré de la différence des fréquences relatives entre le premier sous-texte (f1, ici LexReprAu) et le deuxième (f2, * dans notre exemple), le tout divisé par la fréquence de pondération f0 (fréqtot dans l'exemple). Ce sont ces carrés qui seront triés du plus grand ou plus petit pour indiquer la contribution relative de chaque axe lexical à la distance totale, qui est la somme de ces écarts relatifs. Finalement, la mesure affichée est la racine carrée de la somme des carrés.
Il faut souligner que la mesure de distance (ici: 9.73) ne peut pas être interprétée directement. En soi, le nombre 9.73 ne veut rien dire s'il n'est pas comparé à d'autres résultats de l'application de l'analyseur distance pour un même ensemble de formes lexicales. Pour le moment, nous n'allons donc pas l'interpréter. Deuxièmement, le nombre de dimensions (ici: 5558), signifie que, suite aux limites imposées par le filtre ($*freqtot>3*longueur>2), SATO a utilisé 5558 mots et signes pour distinguer les deux sous-textes.
Point 2 de l'illustration 4. La première colonne du tableau (Fréqtot) correspond à la fréquence de pondération, ici la fréquence de la forme lexicale dans l'ensemble du corpus. La deuxième colonne du tableau, intitulée LxReprA et chapeautée par une étoile, indique sur 100 l'importance de chaque mot dans le sous-texte des représentants des Autochtones et Inuits. La troisième colonne, intitulée ~LxRepr, indique en pourcentage l'importance de chaque mot dans le reste du corpus, ce qui correspond au sous-texte des représentants des autres provinces et du gouvernement fédéral. Le tableau se lit donc comme suit, en prenant pour exemple les trois premières lignes : les mots inuit, inscrits et droits, contribuent le plus à distinguer les deux sous-textes. En effet, sur une base de 100, ils sont respectivement présents 0.30, 0.19 et 0.56 fois dans le premier sous-texte alors qu'ils ne sont présents que 0.01, 0.01 et 0.09 fois dans le second sous-texte.
On remarquera que, même si la différence d'utilisation du mot droits (0,56%-0,09% = 0,47%) est plus grande que celle des mots inuit (0,30%-0,01% = 0,29%) et inscrits (0,19%-0,01% = 0,18%), la contribution du mot droits à la distance du Chi2 est inférieure à celle des deux autres mots. Cela s'explique par la formule de distance du Chi2 qui divise chaque écart de fréquence, mis au carré, par la fréquence de référence fournie dans la première colonne du tableau. Ainsi on pondère les deux premiers mots par 0,03 et 0,01 respectivement, alors que l'on pondère droits par 0,11, ce qui explique qu'il se retrouve en troisième position dans l'explication de la différence de vocabulaire entre les deux sous-textes.
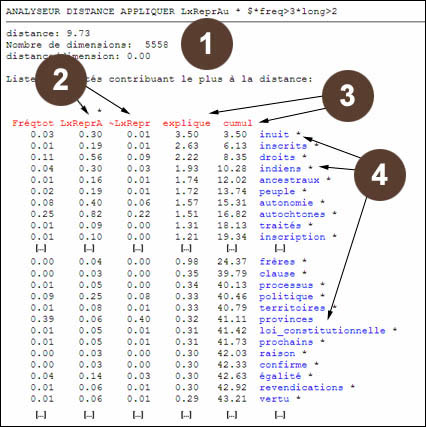
Point 3 de l'illustration 4: Les colonnes intitulées explique et cumul permettent de mieux comprendre la relation entre les deux colonnes précédentes. La première colonne (explique) donne un indice, sur base de 100, de la contribution de chaque mot à la distance entre les deux sous-textes. Ainsi, les mots inuit, inscrits et droits, expliquent la distance entre les deux sous-textes dans une proportion de 3.50%, 2.63% et 2.22%. La seconde colonne, intitulée cumul fait le cumul des valeurs de la colonne précédente (explique). Ainsi, les mots inuit, inscrits et droits contribuent à expliquer 8.35% de la distance lexicale entre les deux corpus. Si l'on descend jusqu'au mot autonomie, on voit que près du sixième de la distance entre les deux sous-textes est expliquée par ces seuls sept mots (inuit, inscrits, droits, indiens, ancestraux, peuple et autonomie). Si on additionnait les contributions de chacune des 5558 mots pris en compte dans le calcul de la distance, on obtiendrait 100%.
Point 4 de l'illustration 4: Dans la colonne des mots, on remarque des étoiles à la suite de certains mots. Ces étoiles indiquent que ces mots sont proéminents dans le sous-corpus des déclarations des représentants des Autochtones et Inuits. Pour trouver le premier mot qui n'est pas suivi d'une étoile, il faut descendre très bas jusqu'au mot provinces. Ce mot est le premier mot qui est sous-présenté dans le premier sous-texte. On comprend donc que les représentants des Autochtones et des Inuits utilisent un vocabulaire très spécifique qui est sous-représenté, voir inexistant, dans le reste du corpus. Les représentants des provinces et du gouvernement fédéral ne parlent pas d'autonomie ou d'inuits et d'indiens de manière aussi significative que les représentants autochtones et inuits.
Nous venons de comparer le sous-texte des déclarations des représentants autochtones et inuits avec le reste du corpus, soit avec les déclarations des représentants des provinces et celles du gouvernement fédéral. Maintenant, nous cherchons à différencier le lexique des déclarations des représentants autochtones et inuits (LexReprAu) avec leur contrepartie fédérale (LxReprFd) uniquement. Pour choisir le premier sous-texte, nous effectuons les mêmes opérations que celles effectuées précédemment (cf. étape #2 Choix de la propriété associée au premier sous-texte). .
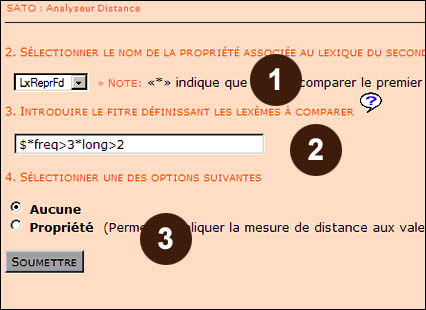
Ensuite, nous allons spécifiquement indiquer à SATO que nous voulons comparer LexReprAu avec LxReprFd (cf. point 1 de l'illustration 5). Pour le reste de l'opération, nous faisons comme nous l'avons fait à l'étape #3 (Choix de la propriété associée au second sous-texte et choix du vocabulaire à comparer), nous allons comparer les mots qui ont une fréquence totale supérieure à trois occurrences et dont le nombre de lettres est supérieur à deux. On clique sur le bouton Soumettre.
Une fois l'analyseur distance appliqué, nous obtenons une page de résultat (cf. illustration 6). Cette page s'interprète de la même manière que la précédente (cf. étape #4 Lecture et interprétation des résultats). Cependant, nous relèverons plusieurs éléments nouveaux.
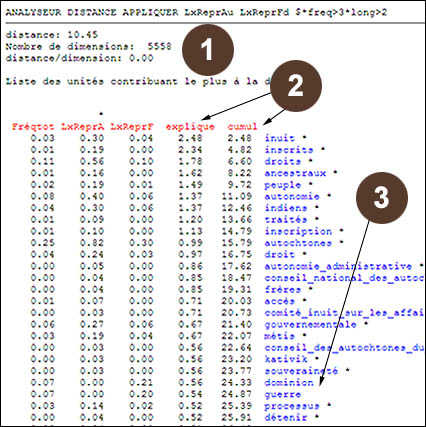
Point 1 de l'illustration 6. L'indice distance est ici de 10.45. On se rappelle que pour le résultat précédent, cet indice était de 9.73. On peut en conclure que, par comparaison, la distance entre LexReprAu et LxReprFd (10.45) est plus grande que celle entre LexReprAu et tout le reste du corpus (9.73).
Point 2 de l'illustration 6. On remarque que la répartition des mots inuit, inscrits, droits, indiens, ancestraux, peuple et autonomie est différente dans le sous-texte des représentants du gouvernement fédéral par rapport à ce qu'elle était dans le sous-texte utilisé lors de la première comparaison. Ainsi, par exemple, le mot inuit explique la différence entre les deux sous-textes avec un pourcentage de 2.48 en comparaison de 3.50% pour le premier tableau. Cela s'explique par le fait que le gouvernement fédéral évoque la situation des Inuits alors que les représentants des provinces ne le font pas. Il en est de même pour le mot indiens qui n'explique que 1.37% de la différence contre 1.93% précédemment.
Point 3 de l'illustration 6. Dans les résultats de l'analyse précédente, le mot provinces était plus présent dans le sous-texte des déclarations des représentants provinciaux et fédéraux. Mais, quand on ne considère que les interventions du fédéral, il disparait de la liste des principales différences. On comprend donc que le fédéral parle peu des provinces .On remarquait également que plus de 40% de la différence était expliqué exclusivement par les mots des représentants autochtones et inuits. Dans le cas de la comparaison présentée ici entre LexReprAu et LxReprFd, la concentration des différences lexicales est moins forte. Aussi, ce sont les mots dominion et guerre qui sont les plus saillants dans le sous-texte des interventions du fédéral.
Comme on le voit, l'analyseur distance permet par comparaison et par contraste entre différentes parties du corpus de mieux saisir leurs les particularités du discours. La comparaison entre deux sous-textes permet d'établir des hypothèses; la comparaison d'un sous-texte avec plusieurs autres sous-textes permet de renforcer ou d'invalider certaines de ces hypothèses. La section suivante de ce guide montre comment retourner aux contextes pour mieux saisir le sens des mots repérés par l'analyseur distance.
7. Utilisation du KWICLe KWIC (ou Keyword in context, mot-clé en contexte) est un outil très utile en analyse de texte assistée par ordinateur. Il permet de situer un mot dans son contexte d'énonciation. Dans SATO, le KWIC est disponible à partir du menu de catégorisation qui apparait dans la fenêtre du bas lorsqu'on clique sur un mot. Dans l'exemple présenté ci-dessous (cf. illustration 7), lorsqu'on clique sur le mot autonomie SATO nous donne accès au menu de catégorisation qui présente diverses informations lexicale et textuelles à propos du mot.
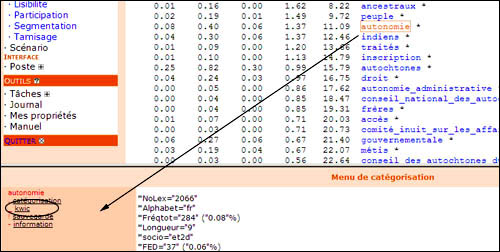
Ensuite, dans le menu de catégorisation, on clique sur le lien KWIC. Ce lien fait apparaitre tous les segments de phrase dans lesquels le mot autonomie apparait tel que présenté dans l'illustration 8 ci-dessous.
